Welcome to Felix's Blog!
这里记录着我的big data学习之路-
hadoop生态
hadoop生态
hadoop生态,最底层为HDFS, 分布式文件系统
在往上,为Hbase,分布式数据库
再上层,就是mapreduce计算框架,storm(流式计算),spark
- mapreduce:批量的数据处理
- storm:实时处理。
- spark:可批量,可实时,stream, SQL,mllib等
再上层,hive(sql引擎),mahout,webserver
- hive:将sql语句翻译成mapreduce,本质就是mapreduce。
- mahout:机器学习的lib
- webserver: pyweb, nginx等
贯穿在整个集群中的,是分布式锁服务zookeeper。
如图:

工程
工程中经常需要使用机器学习技术来挖掘数据价值。
- 机器学习
- 分类算法
- 推荐算法
- 聚类算法
常见业务
搜索场景
以前:人与内容 现在:人与服务
音乐数据来自两类:pgc,ugc
物品(item):属性(features),一般被称为元数据(metadata)。
item- 物品
user- 用户(行为:点击,展现,收藏,支付。。。)
- 不同的行为 用户付出的成本是不一样的,也就是推荐时权重是不一样的
简单的推荐引擎架构

用户点击itemA(港台十大经典歌曲《朋友》)后,系统将item交给引擎处理,引擎会从后端的nosql数据库中查出与itemA相关性较高的item推荐给用户。
推荐实现的步骤:
- 召回阶段(粗排):用token检索item(或者用item检索item),本质是找候选的过程
- 过滤阶段:把候选集合中劣质的item过滤掉
- 排序阶段(精排):把好的item排在前面。
- 截断阶段:topN,取top的过程
技术实现:
- 分词技术:
- 将歌曲名称进行分词,形成多个token
- 如某个token在itemA及另外item中都出现,相关性较强
- 模型打分:
- 对推荐候选进行模型打分。
- 数据库中储存的信息
- 可以是token与item的相关关系(需要实时对item进行分词获取token,指的是用户响应角度)
- 也可以是item与item的相关关系(需要提前离线算好item与item的关系)
item指向token的表是正排表: token指向item的表是倒排表。实时与离线处理的关系
见下图

- mapreduce任务 可以执行更多逻辑
- storm 实时处理的时候 只能执行简单逻辑
- 将实时与离线的数据合并后,插入到数据库中。
- 需要注意实时与离线数据合并的逻辑
基于MapReduce的建库系统
- 目的:建立供检索使用的索引和摘要
- 输入:网页
- 输出: 索引和摘要
- 处理:多轮mapreduce
- 页面分析和处理:parser-extractor
- 页面属性小库输出:splitter
- 小库正排转倒排 invert-index
- 小库合并大库 index merge
-
decision tree学习-2
信息增益的计算
对于如下数据集(feature为grade, bumpyness,speed limit, label为speed)
grade bumpiness speed limit? speed steep bumpy yes slow steep smooth yes slow flat bumpy no fast steep smooth no fast 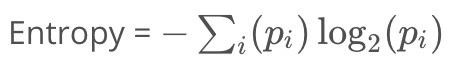
- 如果所有的样本是同一类,他的entropy(熵)为0
- 如果所有样本被均匀分散到所有可用类中,他的entropy为1
计算熵
 p(slow) = 2/4= 0.5
p(slow) = 2/4= 0.5p(fast) = 2/4= 0.5
该节点的entropy为
entropy(node) = -p(slow)*log(p(slow)) - p(fast)*log(p(fast)) = -0.5* log(0.5) - 0.5 * log(0.5) = 1.0
-
机器学习西瓜书笔记-1
过拟合,欠拟合
学习器在训练集上的误差称为“训练误差”, 在新样本上的误差被称为“泛化误差”
我们希望在新样本上表现得很好的学习器。
形成原因
导致过拟合最常见的情况是由于学习能力过于强大,以至于把训练样本中所包含的不太一般的特性都学到了。
欠拟合则多数是由于学习能力低下造成的。
如何规避
欠拟合:一般增加训练数据或训练轮数等
- 在决策树学习中扩展分支
- 在神经网络学习中增加训练轮数
过拟合则比较难规避。过拟合是无法彻底避免的,我们只能缓解或减小其风险。
评估方法
留出法
“留出法”直接将数据集D划分为两个互斥的集合。其中一个作为训练集,另一个作为测试集。
训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响
交叉验证法
cross validation: 先将数据集划分为k个大小相似的互斥集合,每次用k-1个子集作为训练集,余下的那个子集作为测试集;这样就获得了k组测试/训练集,从而可以进行k次训练和测试,最终返回k个测试结果的均值。通常称为
k折交叉验证。为减少因样本划分不同而引入的差别,k折交叉验证通常要随机使用不同的划分重复p次。最终的评估结果是这p次k折交叉验证结果的均值。
调参与最终模型
机器学习常涉及两类参数:
- 算法的参数:超参数。通常由人工设定多个参数候选值后产生模型
- 模型的参数。通过学习来产生多个候选模型
性能度量
错误率与精度
错误率是分类错误的样本数占样本总数的比例
精度则是分类正确的样本数占样本总数的比例
定义

准确率 召回率 F1
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive), 假正例(false positive),真反例(true negative),假反例(false negative)四种情形。TP+FP+TN+FN=样例总数。
分类结果的“混淆矩阵”如下表

准确率: P = TP / (TP+FP)
召回率: R = TP / (TP+FN)
准确率与召回率是一对矛盾的度量。我们经常使用F1 来度量
F1 = 2 * P * R / (P + R)

ROC 与 AUC
ROC全称是“受试者工作特征”曲线。
- ROC纵轴是“真正例率”(True Positive Rate,简称TPR)
- POC横轴是“假正例率”(False Positive Rate,简称FPR)
TPR = TP / (TP + FN)
FPR = FP / (TN + FP)

进行学习器比较时,若一个学习器的ROC曲线被另一个学习器的曲线完全包住,则可断言后者性能优于前者;若两个学习器的ROC曲线发生交叉,则需要比较ROC曲线下的面积,即
AUC (Area Under ROC Curve)AUC可通过对ROC曲线下各部分的面积求和而得。
代价敏感错误率与代价曲线
现实任务中不同错误所造成的损失是不同的。比如:医疗诊断时,有可能将健康人诊断为病人,即FN, 也可能将病人诊断为健康人,即FP; 两者都是犯了错误,但错误的影响时不一样的。前者只是需要进一步检查,后者可能就会丧失治疗的最佳时机。
为权衡不同类型错误所造成的不同损失,可将错误赋予“非均等代价(unequal cost)”
二分类代价矩阵

上图中,cost(ij) 指的是第i类被预测为第j类样本的代价。

-
decision tree学习-1
决策树是一种十分常见的分类方法,是一种监督学习。
监督学习:take examples of inputs and outputs to learn and train an algorithm, then give a new input, use this algorithm to predict an output.
监督学习可以分为classification与regression。classification与regression的分类与input无关,与output有关
- 如果output是连续的,就是regression
- 如果output是离散集合,就是classification
classfiction 与 regression的比较见如下表格:
Input Output classificaction or Regression Credit history lend money or not classification a picture of person high school, college or graduate classification a picture of person age(float) Regression 一些概念
- training set
- 就是一些input,被打好标签(label)。就是一个集合,集合中的item拥有正确的input,output对。
- test set 测试集:
- 通过training set训练出一个算法,然后运用到test set中,算法获取的output与真实output比较,查看效果
- candidate:
- 只有input,output需要通过算法获取。
training set和test set不能一样
决策树
20 questions
20 questions是一个游戏,一个人脑海中想象一个事物,另一个人通过20个是非问题来确定这个事物是什么。策略:
- 最开始问的问题需要尽可能缩小范围,如果最开始问的就是具体问题,如果回答“否”,则基本获取不到信息。
- 问的问题的顺序可能不能颠倒。因为你下一个问题取决于上一个问题中获取的答案。
算法
- Pick best Attribute
- Best: roughly split things in half
- asked question
- follow the answer path
- go to 1
- until got an answer
ID3算法
Loop
- A <— best attribute
- assign A as decision attribute for node
- For each value of A, create a descendent of node
- sort training examples to leaves based upon exactly what values they take on
- if examples perfectly classified, stop;otherwise, iterate over each leaves, picking the best attribute in turn.
中文解释:
- ID3算法是决策树的一种,基于奥卡姆剃刀原理,即用尽量少的东西做更多的事情。ID3算法,基础就是奥卡姆剃刀原理:越是小型的决策树越优于大的决策树。尽管如此,也不总是生产最小的树形结构。
- ID3核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶而下的贪婪搜索遍历可能的决策空间。
奥卡姆剃刀原理:
- 简单有效原理
- 常用于两种或两种以上假说的取舍上:
- 如果对于同一现象有两种或多种不同的假说,我们应当采取比较简单或可证伪的那一种。
ID3推荐:
- good splits at the top
- prefer correct over incorrect ones
- prefer shorter trees over longer trees
information gain公式
information gain:通过挑选特定属性获取信息量的数学方法。
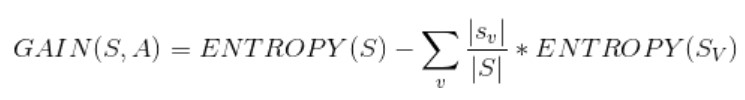
- S: 我们需要查看的训练样本的集合
- A: 特定的特征
entropy公式
entropy: 测量随机性的一种方法。
- Pi是第i类中的样本占总样本数的比例,再对所有类的结果求和
- 熵与数据单一性呈负相关
- 极端情况下,所有样本属于同一类,熵为0。在另一种极端情况下,样本均匀分布在所有类中,熵为最大值1.0。
决策树其他问题
- 何时停止
- 所有条目被正确分类后停止(若有noise,则可能无法每个条目都被正确分类)
- no overfitting
- pruning 修剪 在决策树中,通常算法overfit的原因是,这个决策树太大,太复杂。
- does it make sense to repeat an attribute along a path in the tree?
- no
-
mapreduce任务启动时,报错YarnException Unauthorized request to start container
执行MapReduce任务时,出现如下报错:
[root@master mapreduce_wordcount_python]# bash run.sh rmr: DEPRECATED: Please use 'rm -r' instead. rmr: `/output': No such file or directory 19/02/15 14:50:20 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead. packageJobJar: [./map_new.py, ./red_new.py, /tmp/hadoop-unjar1610102638531802348/] [] /tmp/streamjob2624593896310271836.jar tmpDir=null 19/02/15 14:50:21 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.211.10:8032 19/02/15 14:50:21 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.211.10:8032 19/02/15 14:50:22 INFO mapred.FileInputFormat: Total input paths to process : 1 19/02/15 14:50:22 INFO mapreduce.JobSubmitter: number of splits:2 19/02/15 14:50:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1550239813206_0002 19/02/15 14:50:23 INFO impl.YarnClientImpl: Submitted application application_1550239813206_0002 19/02/15 14:50:23 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1550239813206_0002/ 19/02/15 14:50:23 INFO mapreduce.Job: Running job: job_1550239813206_0002 19/02/15 14:50:24 INFO mapreduce.Job: Job job_1550239813206_0002 running in uber mode : false 19/02/15 14:50:24 INFO mapreduce.Job: map 0% reduce 0% 19/02/15 14:50:24 INFO mapreduce.Job: Job job_1550239813206_0002 failed with state FAILED due to: Application application_1550239813206_0002 failed 2 times due to Error launching appattempt_1550239813206_0002_000002. Got exception: org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container. This token is expired. current time is 1550242223020 found 1550214024349 Note: System times on machines may be out of sync. Check system time and time zones. at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168) at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106) at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:123) at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:251) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) . Failing the application. 19/02/15 14:50:24 INFO mapreduce.Job: Counters: 0 19/02/15 14:50:24 ERROR streaming.StreamJob: Job not successful! Streaming Command Failed!在网上查了下报错,见链接
问题原因为:
This exception occurs when your nodes have different time settings. Make sure that your all 3 nodes have same time n timezone settings and then restart computer.我检查了我的集群,确实发现集群各节点时间不对。
修改好时间,并做好ntpdate同步后,我未重启集群 ,直接重新执行,任务正常